
Message Queues in Database Transactions
Like many scalable SaaS applications, the HighBond platform from Galvanize uses an event-driven architecture. When a state change is made…


Like many scalable SaaS applications, the HighBond platform from Galvanize uses an event-driven architecture. When a state change is made within one service (such as updating a record in the user module), other services are notified via descriptive events posted to a message queue. This allows for loose-coupling of services, leading to better scalability.
In this blog post, we’ll describe our approach for ensuring that events are sent reliably, even in the presence of failure. At Galvanize, we use Ruby on Rails as the main framework for application development, in conjunction with PostgreSQL (via Active Record), and Amazon’s SQS message queue service.
Here’s the basic workflow

An HTTP request comes into the web application server (Ruby on Rails).
The application makes a transactional state change to its local database (PostgreSQL).
A notification event is transmitted to other services, via a message queue (Amazon SQS).
An HTTP response is provided back to the user’s browser.
Although we use Rails, PostgreSQL, and SQS, the concepts are quite general and apply to other web development frameworks, database servers, and message queues.
The Problem
Although it appears simple to generate an SQS message whenever there’s a state change in a service, it’s much harder to ensure it’s done reliably, especially in the face of failure. Here’s the most important rule:
An event should be sent to the message queue if, and only if, the state change has successfully been committed to the originating database.That is, we must avoid having the application change its local database, without the message queue receiving notification of that change. Conversely, the event notification must not be sent if the expected state change didn’t actually happen. Either of these scenarios cause the SaaS application’s services to provide conflicting views of data.
Why is this challenging? Here are three common reasons for failure:
The database transaction, within the source application, may fail and be rolled back.
The message queue may be temporarily unavailable, most likely due to network glitches.
Our application may fail, due to coding issues, or if the underlying operating system becomes unavailable.
Given these potential failures, we came up with several solutions for ensuring atomicity — that is, the data must change consistently throughout the entire system, or none of the changes should occur at all. The system should not allow partial changes to be visible.
Attempt 1 — Send to the Queue From Within the Database Transaction
The first approach we tried, which doesn’t actually work correctly, is to treat the message queue event as part of the database transaction. For example, in Rails we’d use the following syntax:
user.transaction do user.update!(salary: user.salary + 100) queue.send(user.name, user.salary) ... other updates ...endIn this case, we update the user’s salary in the PostgreSQL database, then send a notification to the message queue indicating the user’s new salary. Once the end statement is reached, the entire database change is committed atomically, which is the expected behaviour from PostgreSQL.
This happy path sequence can be visualized in this way:
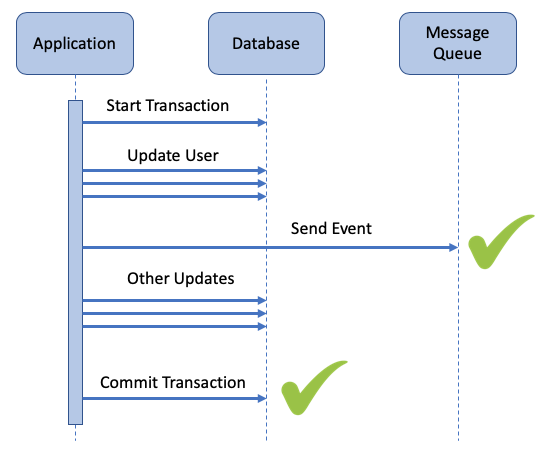
Here’s what happens if the transaction fails — that is, if the ... other updates ... cause an error.

However, this solution fails because the event was already sent to the message queue, and other services believe the change took place, even though it didn’t. Not what we wanted!
Attempt 2 — Send to Queue After Transaction Commits
To work around this failed-transaction problem, our second approach sends the event only when the transaction is known to be successful. Our code example is now:
user.transaction do user.update!(salary: user.salary + 100) ... other updates ...end... if we get here, transaction was successful ...
queue.send(user.name, user.salary)If this code is successful (no rollback exception was thrown), we proceed to send the event on the message queue. There are several ways to do this, but in our case we attached an after_commit hook on the Active Record model. This hook is triggered only when the change is actually committed to the database, but not if it was rolled back.
This sequence can be visualized as:
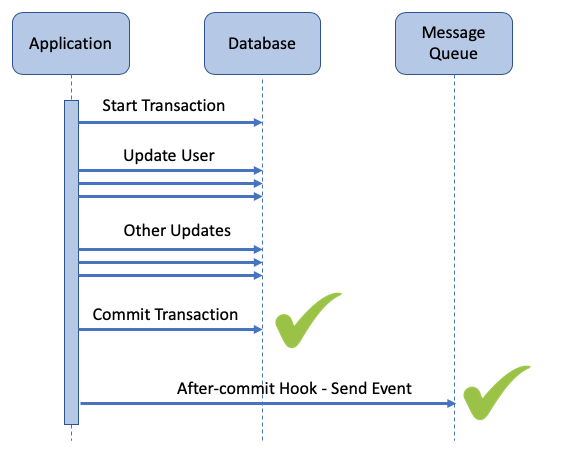
As you’d expect, the failure case is now handled correctly. If the transaction is rolled back, no update is made to the database and no event is sent on the message queue.
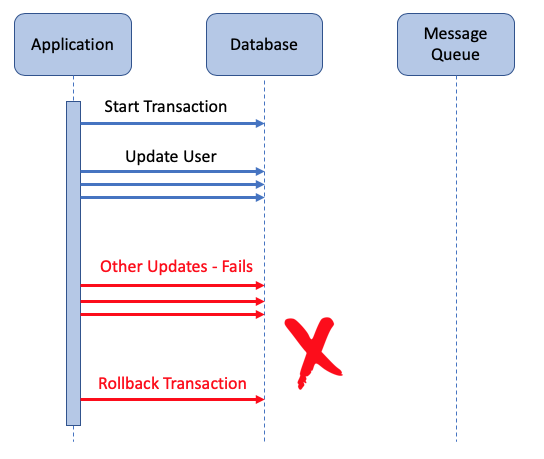
However, this solution isn’t perfect either. What if the database transaction is committed, but for some reason we’re unable to send the event afterwards?

There are two main reasons this might happen:
The application might fail immediately after committing the database change, but before sending the event. This could happen due to badly-written code, or if the underlying OS fails. Although this seems unlikely, it’s sure to eventually happen, especially on a busy system.
A more common problem is when the message queue is unreachable for a period of time, possibly due to network glitches. In this case, the application should repeatedly try to resend the event, until it succeeds.
In the first failure case, the application server restarts and continues processing HTTP requests. However, at that point in time we’ve already lost track of the state change, with no way to know the event hadn’t been sent. In the second failure case, how long should we retry for? Web page requests are supposed to be fast, and the browser is expecting a quick response, so we can’t retry indefinitely.
Attempt 3 — Send Events in a Delayed Job
The main problem with our previous approach is that events were not durable (stored on disk) if they hadn’t yet reached the message queue. Therefore, any programming logic or system failure made us completely lose track of the event.
We need a solution that guarantees the events are durable whenever the database transaction commits. Luckily, the Rails delayed job mechanism provides this ability.
user.transaction do user.update!(salary: user.salary + 100) user.delay.send_event() ... other updates ...endIn Rails, addingdelayto your method call implicitly inserts a snippet of code into a special delayed_jobdatabase table, acting as queue of work to be completed at a future time. A separate Rails server repeatedly pulls code from this table, executing it in the background, usually after the original HTTP request has completed.
This solutions looks similar to our previous cases, but with the addition of a delayed job mechanism:
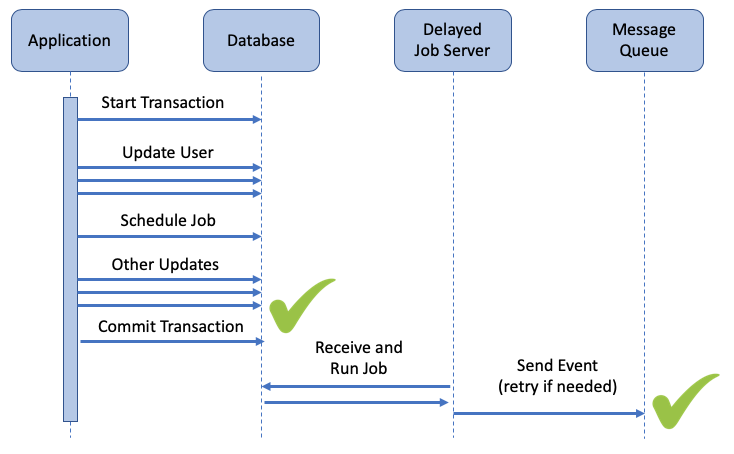
As it turns out, this approach solves all the problems we’ve discussed so far:
By creating a delayed job inside a Rails transaction, the delayed job is only scheduled if the database transaction commits. In Rails, delayed jobs are queued for execution by inserting a record into a PostgreSQL table. If the transaction fails, the job is never committed to the table, so the job is never executed.
Delayed jobs are durable, so even if the application crashes and restarts, the delayed job is still in the database, and the event is transmitted reliably.
If the message queue is unavailable for a period of time, the delayed job can re-execute until it’s successful. Given that it’s running in the background, it will not impact the performance of the end user’s HTTP request. Obviously there must be a limit to the number of retries (it can’t wait forever), but most intermittent failures can be resolved this way.
Naturally, if the database transaction is rolled back, the delayed job won’t be scheduled and the event is never sent:

Is this solution good enough? Yes, it can certainly work, and parts of our system are using this in production. However, we’ve also created a more optimal solution.
Final Solution — Queue the Message Inside the Database, Send it Later
Our final solution is very similar to using delayed jobs, but is more efficient as the system scales. The key problem with delayed jobs is that scheduling a unique job for each event is quite expensive. Ideally we’d like to group multiple events, sending them to the queue as a single batch — a feature provided by SQS to eliminate network round-trips.
Our final solution involves the use of an outbox database table, which is similar to delayed_jobs, but is exclusively for persisting outgoing events. As you’d expect, this table is updated as part of the same database transaction, so changes are rolled back if the main database transaction fails.
Next, instead of using a generic delayed job server that can execute arbitrary code, we have a dedicated outbox_flush loop, focused on grouping events together and posting them to SQS in a batch. By batching into groups of 10 events at a time, the cost of posting to SQS is reduced from 20ms per event (sometimes as high as 50ms), down to an average of 2–5ms per event. In case of failure, the events are always durable, with the flush loop retrying until the events are sent successfully.
Here’s the new architecture:

As before, we have a similar flow of data. We transmit message queue events if, and only if, the main database transaction completes.

To allow this mechanism to be used consistently across our platform, we’ve wrapped this mechanism into a proprietary Ruby gem for reuse within Galvanize’s products.
Conclusion
We’ve shown how to improve scalability and reliability for an event-driven application by combining database transactions with events to be sent on a message queue. There are many reasons for failure, but by integrating events into the main database transaction, making them atomic and durable, we can be confident they will not be lost. We also have the ability to improve our message queue performance by batching together smaller events.
Of course, although these solutions address the problem from the source application’s perspective, there are still plenty of opportunities for failure that we haven’t discussed. Most notably, if the destination service (or services) fail to process the event correctly, we’ll still have a problem with inconsistent data. However, that’s another topic for a different blog post.